intro-to-deep-learning
activation
激活函数。
引入这个东西主要是考虑到若干个线性变换复合后还是线性变换。
所以能起到弯曲决策边界的作用。
| Python |
|---|
1
2
3
4
5
6
7
8
9
10
11
12 | # YOUR CODE HERE: Change 'relu' to 'elu', 'selu', 'swish'... or something else
activation_layer = layers.Activation('elu')
x = tf.linspace(-3.0, 3.0, 100)
y = activation_layer(x) # once created, a layer is callable just like a function
plt.figure(dpi=100)
plt.plot(x, y)
plt.xlim(-3, 3)
plt.xlabel("Input")
plt.ylabel("Output")
plt.show()
|
activation_layer = layers.Activation('relu'):

activation_layer = layers.Activation('elu'):
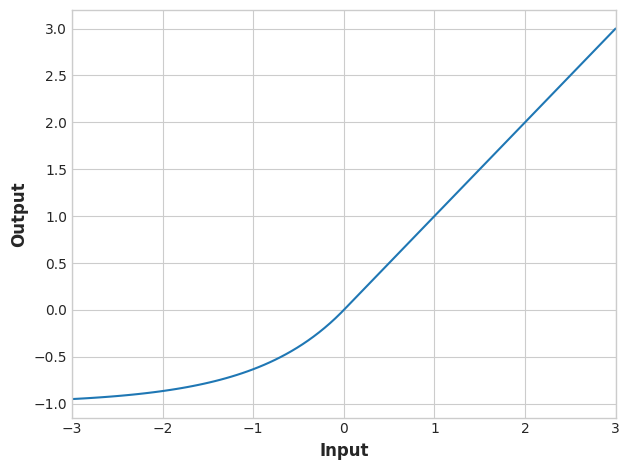
activation_layer = layers.Activation('selu')
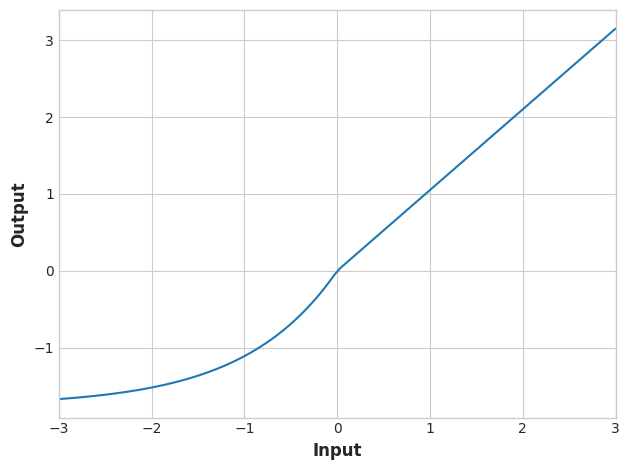
activation_layer = layers.Activation('swish')
| Python |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24 | import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import make_column_transformer, make_column_selector
from sklearn.model_selection import train_test_split
fuel = pd.read_csv('../input/dl-course-data/fuel.csv')
X = fuel.copy()
# Remove target
y = X.pop('FE')
preprocessor = make_column_transformer(
(StandardScaler(),
make_column_selector(dtype_include=np.number)),
(OneHotEncoder(sparse=False),
make_column_selector(dtype_include=object)),
)
X = preprocessor.fit_transform(X)
y = np.log(y) # log transform target instead of standardizing
input_shape = [X.shape[1]]
print("Input shape: {}".format(input_shape))
|
make_column_transformer 的意思是:对不同类型的列用不同的变换器。里边有两个 tuple:
(StandardScaler(), make_column_selector(dtype_include=np.number))
make_column_selector(dtype_include=np.number):自动选出所有数值类型列(int、float 等)。
StandardScaler():对这些数值列做标准化(减均值 / 除标准差 ➜ 均值 0、方差 1)。
(OneHotEncoder(sparse=False), make_column_selector(dtype_include=object))
make_column_selector(dtype_include=object):自动选出所有 object 类型列(通常是字符串类别特征)。
OneHotEncoder(sparse=False):对这些列做独热编码(每个类别变成一组 0/1 列),并返回一个普通的 numpy 数组(不是稀疏矩阵,所以 sparse=False)。
其中,标准化所需的变换参数由训练集确定,所以第一次调用的时候要对训练集使用 fit_transform。随后对测试集使用 transform。
X.shape[1] 是特征的维度(列数)。
preprocessor 的另一种不借助 make_column_selector 的定义
| Python |
|---|
| features_num = ['danceability', 'energy', 'key', 'loudness', 'mode',
'speechiness', 'acousticness', 'instrumentalness',
'liveness', 'valence', 'tempo', 'duration_ms']
features_cat = ['playlist_genre']
preprocessor = make_column_transformer(
(StandardScaler(), features_num),
(OneHotEncoder(), features_cat),
)
|
keras.Sequential
大概就是把神经网络的每一层当成一个元素,这些元素构成一个序列。
| Python |
|---|
| from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Dense(128, activation='relu', input_shape=input_shape),
layers.Dense(128, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(1),
])
|
对于这样的一个对象
| Python |
|---|
| model.compile(
optimizer = 'adam',
loss = 'mae'
)
|
adam
todo: adam 的原理
在 Sequential 的基础上进行训练,顺带可以返回每次训练后的历史记录。
| Python |
|---|
| history = model.fit(
X, y,
# validation_data = (X_valid, y_valid),
batch_size = 128,
epochs = 200
)
|
batch_size 是批次大小
epochs 是训练轮数
利用 pandas 可以绘图
| Python |
|---|
| history_df = pd.DataFrame(history.history)
# Start the plot at epoch 5. You can change this to get a different view.
history_df.loc[5:, ['loss']].plot();
|
如果指定 validation_data 参数,还可以画出一个 val_loss 的信息。据此可以辅助判断欠拟合或者过拟合的问题。
| Python |
|---|
| history = model.fit(
X_train, y_train,
validation_data=(X_valid, y_valid),
batch_size=512,
epochs=50,
verbose=0, # suppress output since we'll plot the curves
)
history_df = pd.DataFrame(history.history)
history_df.loc[0:, ['loss', 'val_loss']].plot()
print("Minimum Validation Loss: {:0.4f}".format(history_df['val_loss'].min()));
|
callbacks.EarlyStopping
可以在 model fit 的时候设置一个 callbacks 参数,来控制什么时候结束训练,避免过拟合。
| Python |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28 | from tensorflow.keras import callbacks
# YOUR CODE HERE: define an early stopping callback
early_stopping = callbacks.EarlyStopping(
min_delta = 0.001,
patience = 5,
restore_best_weights = True
)
model = keras.Sequential([
layers.Dense(128, activation='relu', input_shape=input_shape),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
model.compile(
optimizer='adam',
loss='mae',
)
history = model.fit(
X_train, y_train,
validation_data=(X_valid, y_valid),
batch_size=512,
epochs=50,
callbacks=[early_stopping]
)
history_df = pd.DataFrame(history.history)
history_df.loc[:, ['loss', 'val_loss']].plot()
print("Minimum Validation Loss: {:0.4f}".format(history_df['val_loss'].min()));
|
Dropout
layers 除了 Dense 这种全连接层,还有部分连接层 Dropout,其中参数是连接的百分比。
| Python |
|---|
| # YOUR CODE HERE: Add two 30% dropout layers, one after 128 and one after 64
model = keras.Sequential([
layers.Dense(128, activation='relu', input_shape=input_shape),
layers.Dropout(0.3),
layers.Dense(64, activation='relu'),
layers.Dropout(0.3),
layers.Dense(1)
])
|
sgd
todo: sgd 的原理
对于这样的一个网络
| Python |
|---|
| model = keras.Sequential([
layers.BatchNormalization(input_shape=input_shape),
layers.Dense(512, activation='relu'),
layers.BatchNormalization(),
layers.Dense(512, activation='relu'),
layers.BatchNormalization(),
layers.Dense(512, activation='relu'),
layers.BatchNormalization(),
layers.Dense(1),
])
|
可以这样去训练
| Python |
|---|
| model.compile(
optimizer='sgd',
loss='mae',
metrics=['mae'],
)
|
sklearn.pipeline
pipeline 字面意思流水线。
| Python |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57 | import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.pipeline import make_pipeline
from sklearn.compose import make_column_transformer
hotel = pd.read_csv('../input/dl-course-data/hotel.csv')
X = hotel.copy()
y = X.pop('is_canceled')
X['arrival_date_month'] = \
X['arrival_date_month'].map(
{'January':1, 'February': 2, 'March':3,
'April':4, 'May':5, 'June':6, 'July':7,
'August':8, 'September':9, 'October':10,
'November':11, 'December':12}
)
features_num = [
"lead_time", "arrival_date_week_number",
"arrival_date_day_of_month", "stays_in_weekend_nights",
"stays_in_week_nights", "adults", "children", "babies",
"is_repeated_guest", "previous_cancellations",
"previous_bookings_not_canceled", "required_car_parking_spaces",
"total_of_special_requests", "adr",
]
features_cat = [
"hotel", "arrival_date_month", "meal",
"market_segment", "distribution_channel",
"reserved_room_type", "deposit_type", "customer_type",
]
transformer_num = make_pipeline(
SimpleImputer(strategy="constant"), # there are a few missing values
StandardScaler(),
)
transformer_cat = make_pipeline(
SimpleImputer(strategy="constant", fill_value="NA"),
OneHotEncoder(handle_unknown='ignore'),
)
preprocessor = make_column_transformer(
(transformer_num, features_num),
(transformer_cat, features_cat),
)
# stratify - make sure classes are evenlly represented across splits
X_train, X_valid, y_train, y_valid = \
train_test_split(X, y, stratify=y, train_size=0.75)
X_train = preprocessor.fit_transform(X_train)
X_valid = preprocessor.transform(X_valid)
input_shape = [X_train.shape[1]]
|
binary_crossentropy, binary_accuracy
| Python |
|---|
| model.compile(
optimizer = 'adam',
loss = 'binary_crossentropy',
metrics = ['binary_accuracy']
)
|