lec2-notes¶
https://www.youtube.com/watch?v=4b4MUYve_U8
supervised learning¶
Quote
To describe the supervised learning problem slightly more formally, our goal is, given a training set, to learn a function h : \(\mathcal{X} \rightarrow \mathcal{Y}\) so that \(h(x)\) is a "good" predictor for the corresponding value of \(y\).
For historical reasons, this function h is called a hypothesis.
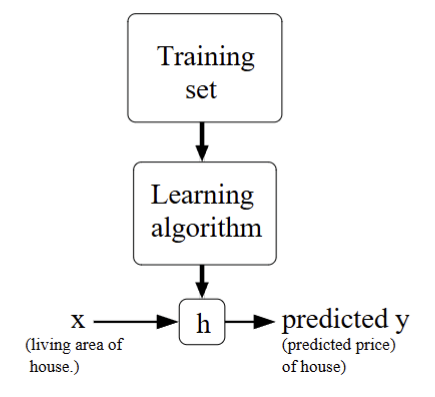
比较简单的想法,就是找个尽量拟合样本点的函数,来预测非样本点处的信息。
一个要注意的记号:对于一组样本,可能会在 superscript 的位置来写 \((i)\) 代表第 \(i\) 个样本点。
Calligraphic¶
形如 \(\mathcal{X,Y,Z}\) 这样的字体叫书法体 Calligrphic。
一般会用这个字体表示 space of values.
linear regression¶
Quote
When the target variable that we’re trying to predict is continuous, such as in our housing example, we call the learning problem a regression prob- lem.
When y can take on only a small number of discrete values (such as if, given the living area, we wanted to predict if a dwelling is a house or an apartment, say), we call it a classification problem.
简单来说 regression 就是考虑相对来说连续的输出。
affine function¶
仿射函数。这里提这个,是说有人定义的 linear function 应该是 \(f(x_1+x_2) = f(x_1) + f(x_2)\), 同时代入 \(0\),应有 \(f(0) = 0\),即不会有常数项。但是我们不在意这个。
cost function¶
对于 hypothesis 函数
其中这些 \(\theta_i\) 是待定的 parameter,可以简单记作一个向量 \(\theta\),从而 \(h(x) = \theta^{T}x\)。
一个 naive 的成本函数
希望选取合适的 \(\theta\) 使得这个东西最小化。
LMS algorithm¶
LMS 是 least mean squares 的缩写。
这个成本函数应该比较特殊。在此引入 gradient descent algorithm,中文中非常熟知的梯度下降算法。
设定一个初始 \(\theta\),以此为基础不断迭代,朝着梯度向量的反方向移动,即微分意义下下降最快的方向
其中 \(\alpha\) 叫作 learning rate。这里 \(:=\) 理解成程序中的赋值,而不是数学里面的定义新变量。
特别地,前面给出的成本函数的梯度函数不难算,
batch gradient descent¶
stochastic gradient descent¶
normal equation¶
英语学习¶
lay the foundation for a lot of work¶
积累一下这个搭配
by convention¶
con-vention 共同习惯,惯例
he's actually really into real estate¶
estate 房地产,之类的。
stuck with some of this terminology¶
the set of technical words or expressions used in a particular subject
termin-ology, 其中 termin- 和边界有关,可以解释成划分边界,从而形成术语。terminal
Seen pictorially,¶
如图所示
the update is proportional to the error term¶
成比例的